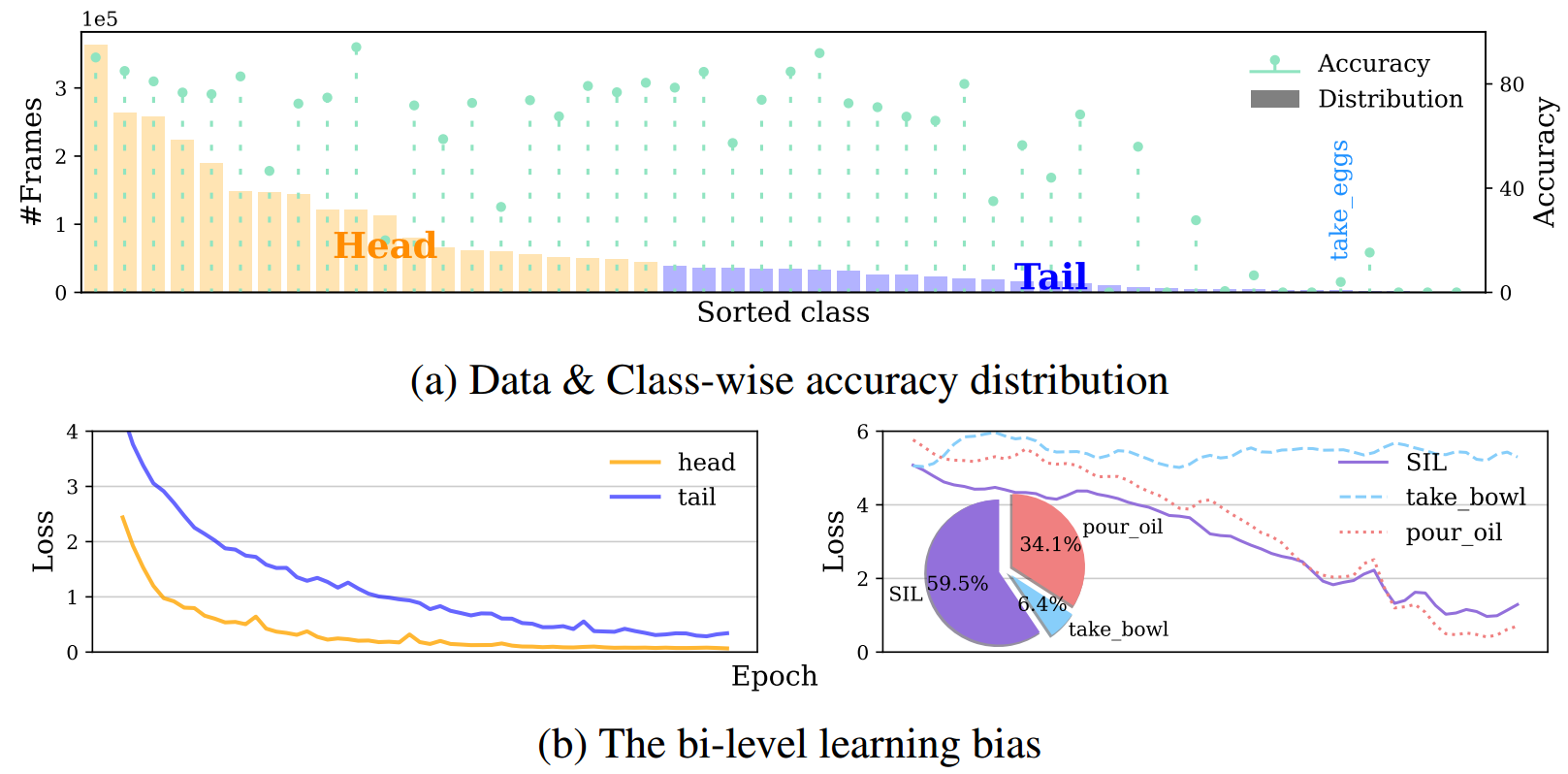
Temporal action segmentation in untrimmed procedural videos aims to densely label frames into action classes. These videos inherently exhibit long-tailed distributions, where actions vary widely in frequency and duration. In temporal action segmentation approaches, we identified a bi-level learning bias. This bias encompasses (1) a class-level bias, stemming from class imbalance favoring head classes, and (2) a transition-level bias arising from variations in transitions, prioritizing commonly observed transitions. As a remedy, we introduce a constrained optimization problem to alleviate both biases. We define learning states for action classes and their associated transitions and integrate them into the optimization process. We propose a novel cost-sensitive loss function formulated as a weighted cross-entropy loss, with weights adaptively adjusted based on the learning state of actions and their transitions. Experiments on three challenging temporal segmentation benchmarks and various frameworks demonstrate the effectiveness of our approach, resulting in significant improvements in both per-class frame-wise and segment-wise performance.
We build a transition-based confusion tensor to assess both class-level and transition-level learning state during training using the corresponding accuracy on training set.
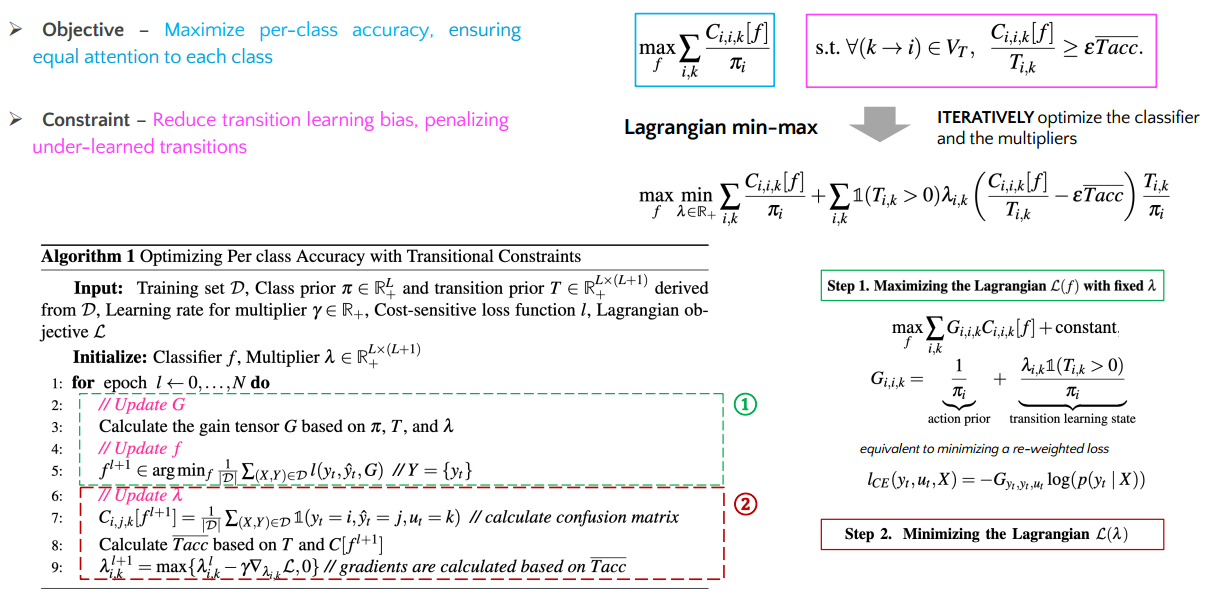
A Cost-sensitive Learning with Constraint is formulated to mitigate both class-level and transition-level biases. We propose a new learning objective to mitigate class-level learning bias. The objective is to maximize per-class accuracy max, ensuring equal attention to all classes. To further reduce the biased transition learning, we define transition constraints to penalize under-learned transitions(those whose accuracies are below the average) and thus reduce the learning variance. We resort to Lagrangian formulation to relax the constraints, and reformulate the problem as an equivalent Lagrangian min-max problem. The Lagrangian is solved iteratively by optimizing the neural model $f$ and the multipliers $\lambda$. and minimizing λ while keeping f fixed
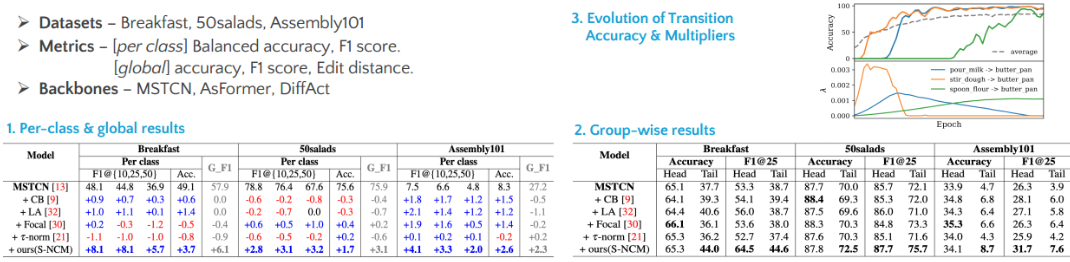
Our method is evaluated on several datasets and metrics. Our work shows good performance on (1) per class performance as well as global performance. (2) tail class performance without sacrificing head performance.
@article{pang2024csl,
title={Cost-Sensitive Learning for Long-Tailed Temporal Action Segmentation},
author={Zhanzhong Pang and Fadime Sener and Shrinivas Ramasubramanian and Angela Yao},
journal={BMVC},
year={2024}}