Online Action Detection (OAD) detects actions in streaming videos using past observations. State-of-the-art OAD approaches model past observations and their interactions with an anticipated future. The past is encoded using shortand long-term memories to capture immediate and longrange dependencies, while anticipation compensates for missing future context. We identify a training-inference discrepancy in existing OAD methods that hinders learning effectiveness. The training uses varying lengths of shortterm memory, while inference relies on a full-length shortterm memory. As a remedy, we propose a Context-enhanced Memory-Refined Transformer (CMeRT). CMeRT introduces a context-enhanced encoder to improve frame representations using additional near-past context. It also features a memory-refined decoder to leverage near-future generation to enhance performance. CMeRT achieves state-of-theart in online detection and anticipation on THUMOS’14, CrossTask, and EPIC-Kitchens-100.
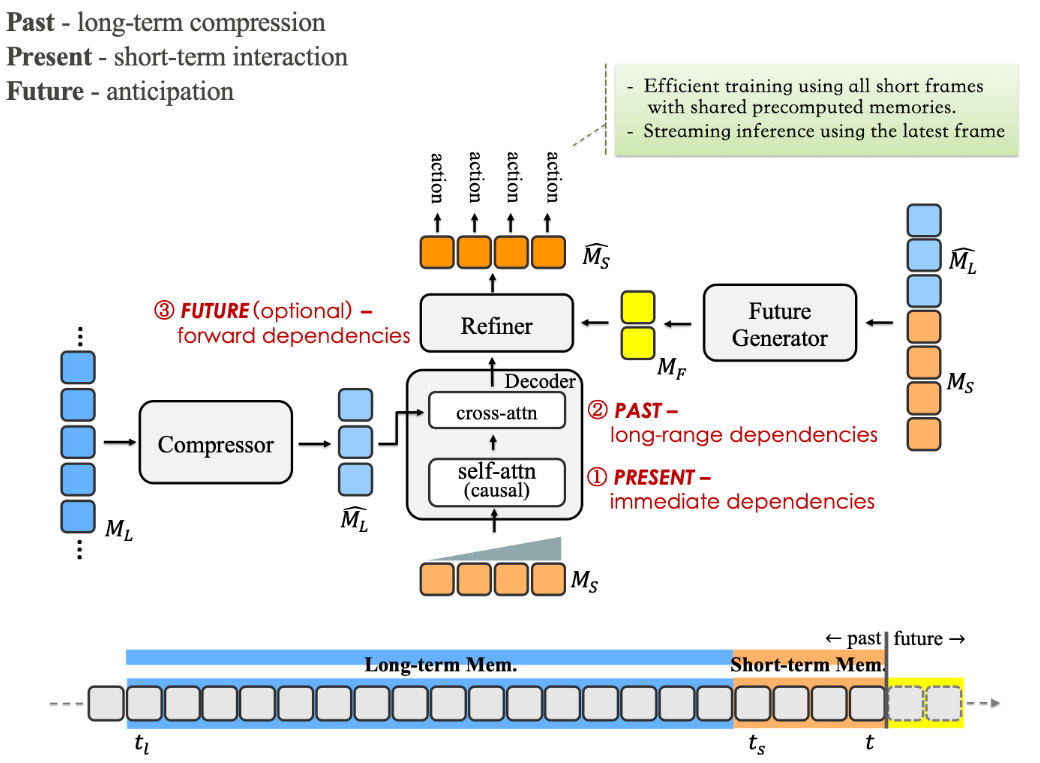
SOTA Online Action Detection is structured in terms of three time zones: the past, the present, and the future. The past offers long-term context that happened a while ago but still matters. The present captures short-term of recent observations, which are most directly relevant to the ongoing action. The future denotes upcoming frames that are not yet visible but often used as anticipation of what might happen next.
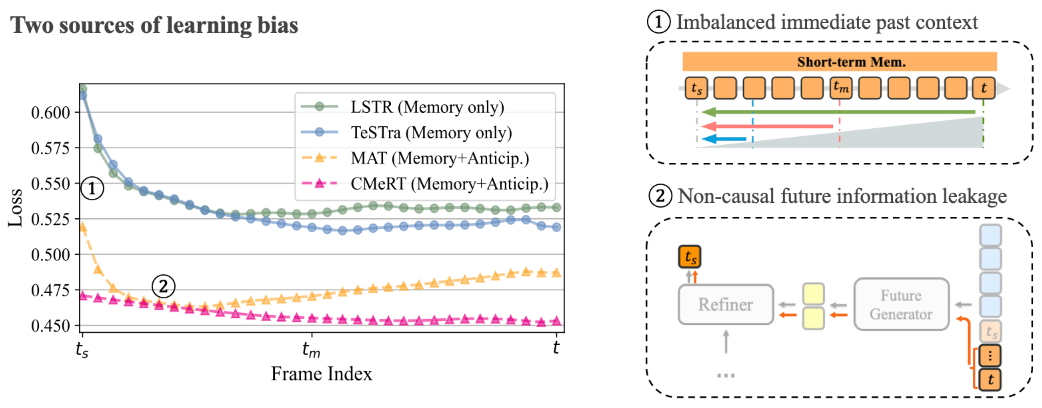
A training-inference mismatch introduces two biases that hinder accurate modeling of the latest frame, which is crucial for inference. First, the causal mask in self-attention creates context imbalance across short-term frames: the latest frame has full context, while the earliest has none. This leads to poor representations for early frames, increasing their loss and degrading the model’s ability to predict the latest frame. Second, using anticipation as pseudo-future introduces non-causal leakage—early frames indirectly access future context, favoring intermediate frames. This results in a valley-shaped loss curve and biased learning that harms final-frame prediction.
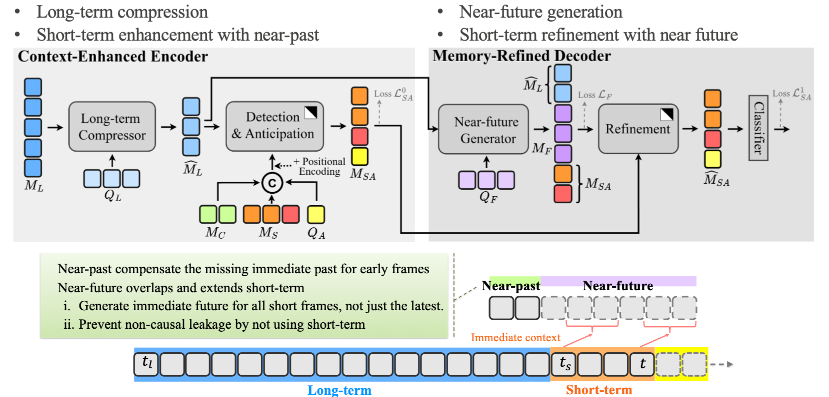
CMeRT introduces two extra memories; 1) the near-past, that supplement the context for earlier frames in short-term memory. 2) generated near-future that serves as pseudo-future and avoids information leakage. Unlike standard anticipation, which only serves as near-future for the latest frame but acts as distant future for earlier ones, the near-future we designed overlaps and extends beyond the short memory to serve a pseudo near-future for all short-term frames. Based on these two extra context, CMeRT includes a context-enhanced encoder, and a memory-refined decoder. The context-enhanced encoder leverages the near-past to supplement the context for earlier frames in short-term memory, improving training and yielding better frame representations. The memory-refinement decoder enhances short-term memory using generated near-future frames. our anticipated future is derived from long-term memory, preventing non-causal leakage and reducing the learning bias toward intermediate frames
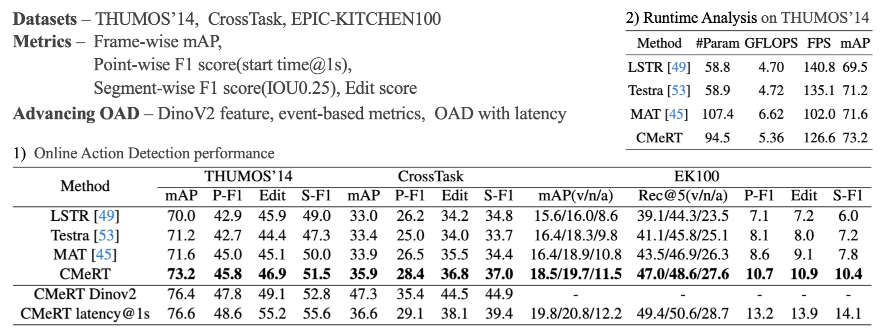
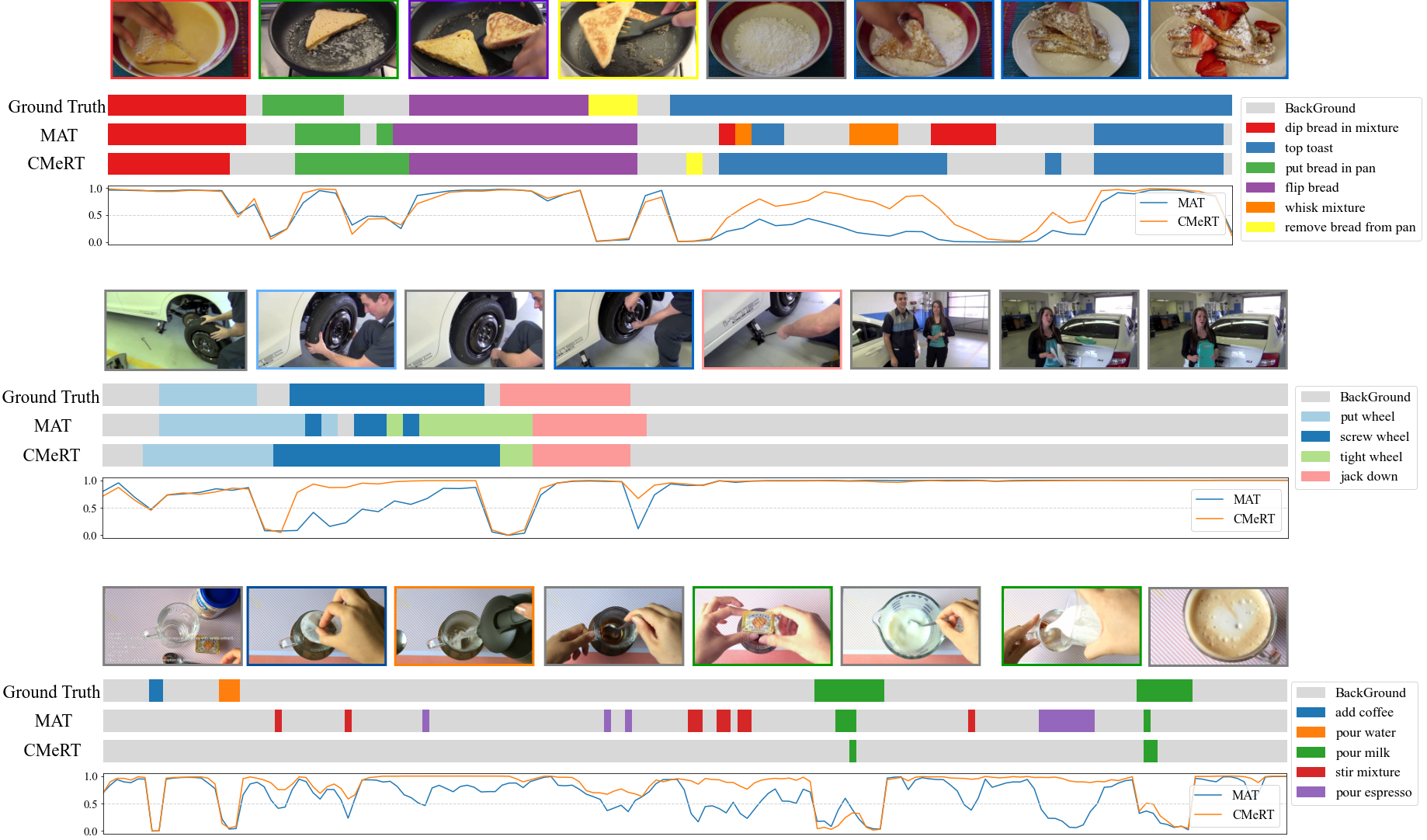
We evaluate our method on three benchmark datasets using frame-wise, point-wise, and segment-wise metrics. The results show consistent improvements across all metrics, while maintaining efficient runtime performance. To further demonstrate robustness, we also test our approach with advanced DINOv2 features. Based on these findings, we propose a new benchmark for online action detection, including updated datasets, features, and evaluation protocols. Additionally, we introduce a new baseline for online action detection with latency constraints.
@article{pang2025cmert,
title={Context-Enhanced Memory-Refined Transformer for Online Action Detection},
author={Zhanzhong Pang and Fadime Sener and Angela Yao},
journal={CVPR},
year={2025}}